
Che cos’è l’Intelligenza Artificiale?
Prima di addentrarci nel significato di Intelligenza Artificiale, vediamo in quali situazioni della vita quotidiana potreste aver già incontrato questa tecnologia. Gli assistenti virtuali ne sono un esempio molto comune. Da Alexa di Amazon a Google Assistant, passando per Siri di Apple e Bixby di Samsung, li troviamo un po’ ovunque: sui telefoni, nelle auto, sugli orologi e nelle case. Questi strumenti possono riprodurre musica, impostare sveglie, fornire previsioni del tempo, cercare informazioni online, inviare messaggi e molto altro. La loro abilità nel svolgere queste funzioni deriva dall’uso di questa tecnologia. Ma cosa si intende esattamente per Intelligenza Artificiale? E come la impiegano gli assistenti virtuali?
L’IA è un campo della scienza informatica che si concentra sullo sviluppo di software e hardware in grado di eseguire compiti che, normalmente, richiederebbero l’intelligenza umana. Questi compiti possono includere il riconoscimento della voce (come negli assistenti virtuali), l’apprendimento, la pianificazione, la comprensione del linguaggio naturale e così via.
Tipi di Intelligenza Artificiale
Ci sono diversi tipi di IA e vengono solitamente classificati in base a due criteri principali, in base la tecnologia utilizzata ed in base alle funzionalità. Dal punto di vista della tecnologia, l’IA può essere classificata a sua volta in tre tipi: l’IA basata su regole, l’IA basata su statistiche e l’IA basata su apprendimento profondo (o deep learning).
Dal punto di vista delle funzionalità, invece, l’IA può essere suddivisa in due categorie principali: l’IA debole (o limitata) e l’IA forte (o generale). L’IA debole è progettata per svolgere un compito specifico, come riconoscere la voce o riprodurre musica su richiesta. Al contrario, l’IA forte può eseguire qualsiasi compito intellettivo normalmente eseguito da un essere umano.
Tuttavia, l’IA non è solamente una simulazione delle capacità cognitive umane in un computer. È anche un insieme di metodi, tecniche e algoritmi che permettono a un computer di eseguire questi compiti. Questi metodi possono includere, il machine learning, deep learning, l’elaborazione del linguaggio naturale o NLP.
Big Data: Cosa Significa?

Uno dei primi concetti che dobbiamo affrontare parlando dell’IA moderna è sicuramente il concetto di “big data”. Ma cosa significa esattamente il termine “big data” e perché è così importante per lo sviluppo dell’IA? Quando si parla di big data ci si riferisce ad insiemi di dati estremamente grandi che generalmente non possono essere elaborati o analizzati dai programmi di calcolo tradizionali. Perché un dato possa essere considerato “big data”, deve essere disponibile in grandi quantità, provenire da diverse fonti e essere raccolto a un alto ritmo. Possiamo riassumere questi aspetti con i tre “V” del big data: volume, varietà e velocità.
Ma vediamo qualche esempio concreto. Un esempio di big data è rappresentato dai dati registrati nelle scatole nere degli aeroplani, che includono registrazioni vocali dell’equipaggio di volo e informazioni sulle prestazioni dell’aeromobile. Durante un volo di 30 minuti, un solo aereo può generare oltre 10 TB di dati. Altro esempio è rappresentato dai dati delle borse valori, che registrano le decisioni di acquisto e vendita di azioni effettuate dai clienti. La Borsa di New York, ad esempio, genera circa 1 TB di nuovi dati di transazioni al giorno. Infine, abbiamo l’Internet delle Cose (IoT), che consente alle aziende di raccogliere dati attraverso dispositivi come sistemi domotici intelligenti, robot aspirapolvere, smart TV, dispositivi mobili e tracker di fitness indossabili. Questi dispositivi generano un’enorme quantità di dati che possono essere utilizzati per scopi di analisi e apprendimento automatico.
Ma perché il big data è così importante per l’IA? In realtà, il big data e l’IA sono strettamente collegati. Senza dati, non ci sarebbe l’intelligenza artificiale. Senza intelligenza artificiale, tutti quei dati non verrebbero utilizzati in modo efficiente, soprattutto in tempo reale.
Machine Learning: Cos’è?
Il machine learning è una branca dell’IA che utilizza algoritmi per consentire alle macchine di migliorare le proprie prestazioni attraverso l’esperienza. In altre parole, il machine learning consente alle macchine di imparare senza essere programmate esplicitamente per ogni specifico compito.
Come funziona esattamente il machine learning? Il processo di machine learning inizia con l’input dei dati di addestramento in un algoritmo di machine learning. A seconda del tipo di dati di addestramento, l’algoritmo elabora le informazioni e restituisce un risultato o una previsione basata sul modello creato. Se la previsione è accurata, il modello viene adottato e utilizzato. Se la previsione non è accurata, l’algoritmo viene sottoposto a ulteriori addestramenti fino a raggiungere risultati accettabili. In questo modo, l’algoritmo di machine learning è in grado di apprendere continuamente e di produrre risposte sempre più precise nel tempo.
Tipi di Machine Learning
Il machine learning può essere suddiviso in tre categorie principali: il machine learning supervisionato, il machine learning non supervisionato e il machine learning per rinforzo. Queste categorie si differenziano per il tipo di dati utilizzati e per il modo in cui gli algoritmi elaborano le informazioni.
Il machine learning supervisionato Questo tipo di apprendimento avviene quando un algoritmo apprende da un insieme di esempi pre-etichettati. In altre parole, gli vengono forniti dei dati di input insieme al corrispondente output desiderato. L’algoritmo “apprende” quindi una funzione che mappa l’input all’output. Questa funzione può poi essere utilizzata per prevedere l’output dato un nuovo input. Per esempio, un algoritmo di apprendimento supervisionato potrebbe essere addestrato per riconoscere gli oggetti in una foto. Ad esso verrebbero fornite molte foto di oggetti (input) con le relative etichette (output), come “cane”, “gatto”, “automobile”, ecc. Dopo l’addestramento, l’algoritmo dovrebbe essere in grado di etichettare correttamente nuove foto di oggetti.
Il machine learning non supervisionato, Questo tipo di apprendimento avviene quando un algoritmo deve trovare modelli o relazioni in un insieme di dati non etichettati. In altre parole, l’algoritmo non ha accesso a un output desiderato a cui mirare. Invece, deve trovare strutture o relazioni nascoste nei dati. Ad esempio, un algoritmo di apprendimento non supervisionato potrebbe essere utilizzato per segmentare una base di clienti in vari gruppi in base alle loro preferenze di acquisto. L’algoritmo non conosce in anticipo quali potrebbero essere questi gruppi, ma deve trovarli analizzando i dati.
Infine, il machine learning per rinforzo Questo tipo di apprendimento è leggermente diverso dai precedenti. Un algoritmo di apprendimento per rinforzo “apprende” interagendo con il suo ambiente. Riceve un feedback sotto forma di “ricompense” o “punizioni” in base alle azioni che compie. L’obiettivo dell’algoritmo è massimizzare la somma totale delle ricompense. Ad esempio, un algoritmo di apprendimento per rinforzo potrebbe essere utilizzato per addestrare un agente a giocare a un videogioco. L’agente riceve una ricompensa ogni volta che raggiunge un obiettivo nel gioco (come ottenere un punteggio alto) e una punizione ogni volta che fallisce (come perdere una vita). Attraverso molti tentativi ed errori, l’agente “apprende” la strategia migliore per giocare al gioco.
Deep Learning: Cosa Significa?
Il deep learning è una branca del machine learning che utilizza reti neurali artificiali per consentire alle macchine di elaborare e comprendere le informazioni in modo simile all’apprendimento umano. Le reti neurali sono composte da un grande numero di interconnessioni, chiamate neuroni artificiali, che lavorano insieme per analizzare e dare un significato ai dati.
Queste reti neurali possono apprendere e prendere decisioni più velocemente rispetto agli esseri umani, in alcune situazioni.
Tuttavia, è importante sottolineare che il deep learning non rappresenta una soluzione perfetta per ogni situazione. È più complesso e richiede maggiori risorse di calcolo, quindi potrebbe non essere adatto a tutte le applicazioni. È necessario valutare attentamente il problema e i requisiti specifici del vostro progetto prima di optare per una tecnica di deep learning.
Processo di Funzionamento del Deep Learning
Per comprendere appieno il funzionamento del Deep Learning, è essenziale familiarizzare con il concetto di “rete neurale”. Una rete neurale è un sistema di nodi interconnessi che mira a emulare il modo in cui il cervello umano elabora informazioni e riconosce pattern. Esplorando la progettazione e il funzionamento di una rete neurale, diventa chiaro perché questa descrizione, seppur semplice, risulta accurata.
Struttura di una Rete Neurale Artificiale:
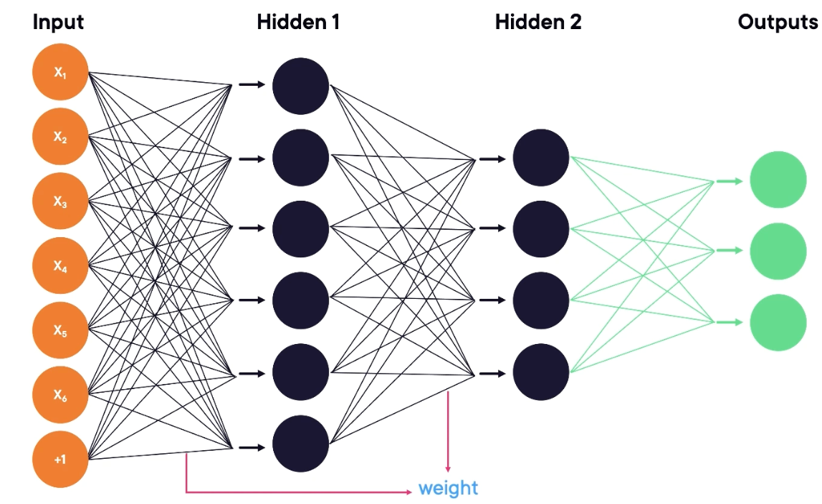
Una rete neurale artificiale è composta da tre tipi di layer: il layer di input, uno o più layer nascosti (hidden layer) e il layer di output. Ogni layer contiene una serie di neuroni artificiali, rappresentati da nodi circolari, che permettono il flusso dei dati e dei calcoli. Le connessioni tra i neuroni sono rappresentate da frecce che collegano l’output di un neurone all’input di un altro. Le connessioni tra i neuroni sono caratterizzate da pesi, che determinano l’importanza di ciascuna connessione. I pesi vengono determinati dalla rete neurale attraverso un processo di prova ed errore.
Propagazione in Avanti e Retropropagazione: Il funzionamento del Deep Learning può essere suddiviso in due fasi principali: la propagazione in avanti (forward propagation) e la retropropagazione (backpropagation). Durante la propagazione in avanti, i dati fluiscono dal layer di input al layer di output. I dati vengono moltiplicati per i pesi associati alle connessioni e successivamente elaborati dai neuroni attraverso funzioni di attivazione. Questo processo consente alla rete neurale di generare una previsione o un output basato sui dati di input. Successivamente, durante la retropropagazione, l’output prodotto viene confrontato con l’output desiderato. La rete neurale utilizza questa discrepanza per regolare i pesi delle connessioni e migliorare le sue prestazioni. La retropropagazione viene iterata più volte fino a quando la rete neurale raggiunge una precisione accettabile nella risoluzione del problema.
Cos’è l’Elaborazione del Linguaggio Naturale (NLP)
Introduzione:
L’Elaborazione del Linguaggio Naturale (NLP) è un campo dell’intelligenza artificiale (AI) che si occupa di far interagire i computer con il linguaggio umano in modo naturale e comprensibile. Attraverso l’utilizzo di algoritmi e tecniche avanzate, l’NLP consente ai computer di comprendere, interpretare e generare testo e linguaggio parlato.
Definizione e Obiettivi dell’NLP:
L’Elaborazione del Linguaggio Naturale si concentra sulla comprensione e l’elaborazione automatica del linguaggio umano in modo simile a come gli esseri umani lo fanno. L’obiettivo principale dell’NLP è consentire ai computer di comprendere il significato e il contesto del linguaggio umano, consentendo loro di interagire con gli utenti in modo più naturale ed efficace.
Principali Componenti dell’NLP:
L’Elaborazione del Linguaggio Naturale coinvolge diverse componenti fondamentali, tra cui:
- Tokenizzazione: La tokenizzazione è il processo di suddivisione di un testo in unità più piccole chiamate token, come parole, frasi o caratteri. Questa fase è essenziale per la successiva analisi e comprensione del testo.
- Analisi morfologica: Questa analisi aiuta a comprendere la struttura delle parole e le loro relazioni all’interno di una frase.
- Parsing sintattico: Il parsing sintattico analizza la struttura grammaticale di una frase, identificando le dipendenze tra le parole e costruendo alberi di sintassi che rappresentano la struttura grammaticale della frase.
- Analisi semantica: L’analisi semantica si concentra sulla comprensione del significato delle frasi. Attraverso l’utilizzo di algoritmi e modelli, l’analisi semantica cerca di identificare il significato delle parole e delle frasi in base al contesto.
Applicazioni dell’NLP:
L’Elaborazione del Linguaggio Naturale ha diverse applicazioni pratiche in vari settori, tra cui:
- Assistenza virtuale e chatbot: I chatbot e le assistenti virtuali sfruttano l’NLP per comprendere e rispondere alle richieste degli utenti in modo automatico e interattivo.
- Traduzione automatica: L’NLP è utilizzato per sviluppare sistemi di traduzione automatica che consentono di tradurre testi da una lingua all’altra in modo rapido ed efficiente.
- Ricerca e analisi del testo: L’NLP viene utilizzato per estrarre informazioni significative dai testi, come l’indicizzazione e il raggruppamento dei documenti, l’analisi delle opinioni e l’estrazione delle entità.
- Riconoscimento vocale: L’NLP è fondamentale per i sistemi di riconoscimento vocale che consentono ai computer di comprendere il linguaggio parlato e trasformarlo in testo scritto.
- Generazione di testo automatica: L’NLP può essere utilizzato per generare automaticamente testi come report, articoli o descrizioni basandosi su dati o input specifici.